Bài này sẽ nói về cách chúng ta sử dụng DOM để làm việc với 1 file XML .
Tại sao lại dùng DOM ?
Chúng ta sử dụng DOM vì SAX có một nhược điểm là nó không cho chúng ta truy suất tới bất kì một điểm nào ngay lập tức trong file xml mà phải đọc thông tin 1 cách tuần tự từ trên xuống dưới.Và việc đọc dữ liệu từ file XML dùng SAX rất phức tạp đặc biệt cho những chức năng tìm kiếm phức tạp do không hỗ trợ DTD , không có nhiều thông tin về Lexical và không thể dùng SAX để cập nhật thông tin của 1 file XML .
DOM :
Để khắc phục các nhược điểm kể trên của SAX thì người ta tạo ra DOM.Nó có tất cả các ưu điểm của SAX và khắc phục được các điểm hạn chế kể trên.
Lợi ích của DOM đem lại :
_Truy suất được nhiều tài liệu để quản lý các cấu trúc dữ liệu phức tạp cho phép chúng ta thay đổi dữ liệu trong file XML
_ Cho phép chúng ta truy suất đến 1 thành phần ngẫu nhiên và liên tục trong file XML
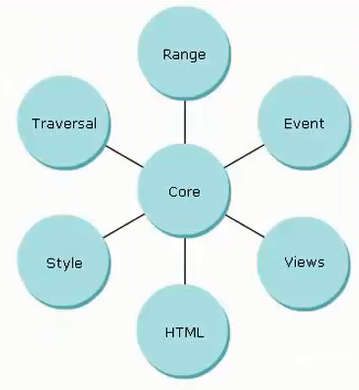
Các thành phần của DOM : DOM có cấu trúc hình cây.Chúng ta có thể tham khảo qua ảnh sau :
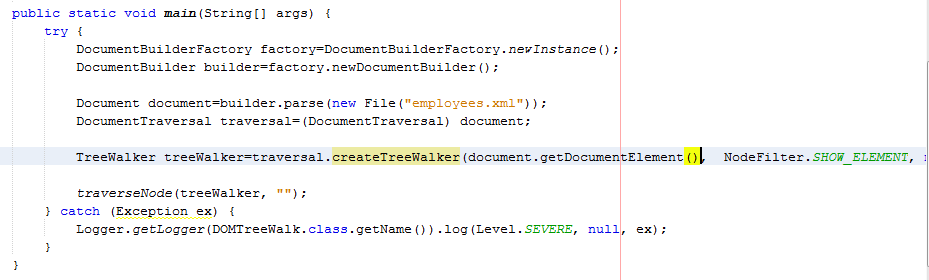
Cách thức làm việc với DOM :
_Gần như giống với SAX
.trong SAX có parser còn ở đây ta có Documentbuilder,muốn có documentbuilder ta có documetbuilder factory.
Nhận xét :
_ DOM có tất cả các ưu điểm và giải quyết được tất cả các nhược điểm của SAX.
_-DOM sẽ phân tích toàn bộ dữ liệu XML trong bộ nhớ trong khi SAX chỉ phân tích một phần nhỏ trong bộ nhớ